
웹 성능 개선에 관해 공부를 하다가, 성능 개선 방법을 떠올리기 위해선 우선적으로 브라우저의 작동 원리에 대한 이해가 선행되어야 한다는 것을 깨닫게 되었다. 그러다 마주치게 된 것이 MDN의 "Populating the page: how browsers work"인데, 내용이 너무 좋아서 모든 페이지의 내용을 워드바이워드 읽어가며 공부했다. 본 포스팅은 이 글을 메인 레퍼런스로 공부하며 기록한 내용을 각색한 것이며, 글을 읽고 브라우저 작동 순서로부터 얻을 수 있는 성능 개선에 관한 나름의 인사이트를 정리한 글이다.
대기시간 && 싱글 스레드 브라우저
대기시간(latency)와 싱글 스레드(Single-threaded) 브라우저는 웹 성능을 이해하는데 있어서 가장 중요한 두 가지 요소이다. 클라이언트에서 서버로 요청을 보내고 그에 대한 응답을 받기까지의 시간과 싱글 스레드 방식으로 동직하기 때문에 작업 처리 면에서 발생할 수 있는 속도 및 시간 이슈가 웹의 성능에 주요한 영향을 끼치기 때문이다.
대기시간과 브라우저가 싱글 스레드라는 특징, 이 두가지가 웹 성능에 큰 영향을 끼친다고 했을 때, 그렇다면 웹 성능을 개선할 수 있는 방법은 크게 아래 두 가지로 나눌 수 있을 것이다:
➡️ 대기시간을 줄이기 위해 할 수 있는 시도 👍
➡️ 브라우저가 싱글 스레드인 점을 고려해서 할 수 있는 시도 👍
대기 시간을 줄이는 것, 그리고 싱글 스레드인 점을 고려해서 적용할 수 있는 시도들을 알기 위해선, 브라우저가 서버로 요청을 보낸 뒤 그 응답이 도달해서 유저의 화면에 그려지기까지 일련의 과정들이 어떻게 진행되는지 잘 이해하고 있어야 한다.
그렇다면, 브라우저 화면의 링크를 클릭하거나 주소창에 방문하고 싶은 사이트의 주소를 적은 뒤 엔터를 누르면 어떤 일이 일어날까? 유저가 링크를 클릭하거나 엔터를 누르는 그 순간부터 방문을 원했던 웹사이트의 모습이 브라우저에 그려지기까지의 과정은 아래과 같이 크게 네가지 단계로 나눌 수 있다.
1. 연결 준비 단계 (Navigation)
2. 서버: 응답 (Response)
3. 클라이언트: 파싱 (Parsing)
4. 랜더 (Render)
그러면 이 단계들이 무엇을 뜻하는지 하나씩 차근차근 살펴보면서, 앞서 말한 "대기시간을 줄이기 위해 할 수 있는 시도"와 "브라우저가 싱글 스레드인 점을 고려해서 할 수 있는 시도"에 대해 고민해보도록 하자! 😃
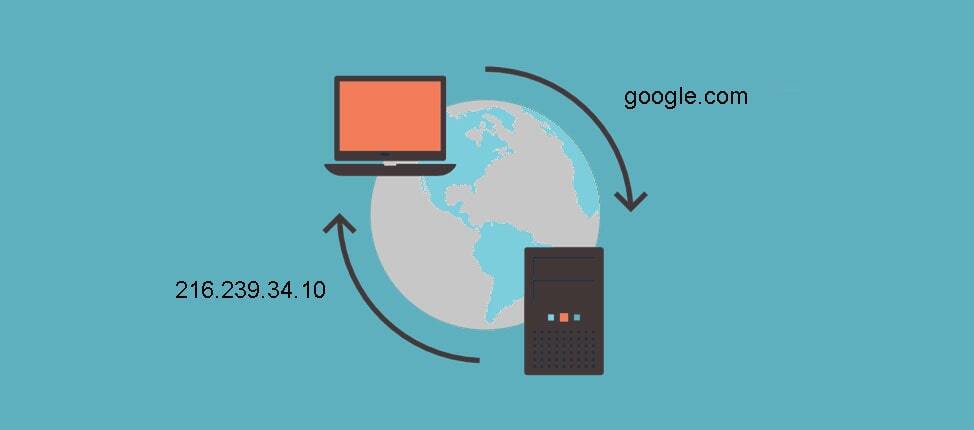
1. 연결 준비 단계, 탐색 (Navigatioin) 🧭
1-1. IP 주소를 얻어라!
모든 거사(?!)는 유저가 브라우저를 통해 링크를 클릭하거나 주소창에 사이트의 주소를 쓰고 엔터를 누르는 순간 발생한다. 먼저 우리는 'www.google.com'과 같은 도메인을 사용해서 사이트에 접속하게 된다. 그런데, 이러한 도메인들은 내가 원하는 정보가 저장되어 있는 컴퓨터로 직통 연결을 해주지 않는다. 이 도메인들은 DNS 네임 서버(name server)로 전송되며, 네임 서버는 도메인에 해당되는 IP 주소를 유저의 브라우저로 전송해준다.
이렇듯 네임 서버에 요청해서 실제 방문하고 싶은 사이트의 IP 주소를 받아오는 것을 DNS lookup이라고 한다. 만약 유저가 해당 사이트를 이전에 방문한 적이 있다면, 캐시에 남아있어서 DNS lookup 요청을 하지 않고 곧바로 이미 알고 있는 IP 주소로 요청을 할 수도 있다.
DNS lookup은 보통 hostname 하나 당 한번이면 되지만, 만약 요청한 페이지에 다른 사이트들에서 참조하는 내용이 있다면 각자의 고유한 hostname들에 대해서도 모두다 한번씩 DNS lookup을 거쳐야 한다. 이 다른 사이트에서 참조하는 내용엔 폰트라던가, 이미지, 광고 등이 모두 포함된다. 이들이 모두 다른 hostname을 가졌을 경우엔, 각자에 대해 DNS lookup을 요청한다는 뜻이다.
유저가 접속한 디바이스가 모바일 기기일 경우엔, 모바일 기기에서 DNS 서버로 가는 여정 중간에 추가로 Cell tower까지 거쳐야 하기 때문에 만약 유저의 현재 위치가 cell tower, 그리고 서버와도 거리가 멀다면 대기 시간이 더 길어질 수 있다.
1-2. 서버와의 연결을 준비하라 1편 (TCP Handshake: TCP 세션 협상)
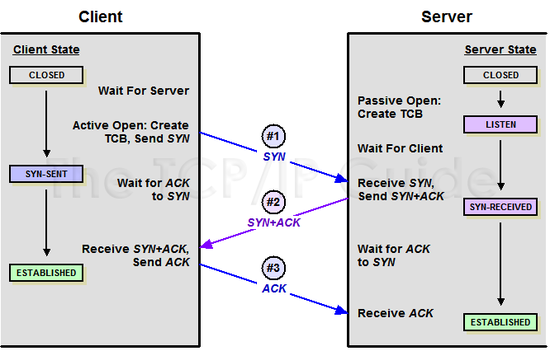
자, DNS lookup을 통해 IP 주소를 얻었다면, 이제 정말 내가 방문하고 싶던 사이트를 가진 서버와 만나기 바로 직전의 상황이 된 것이다. 그런데, 아직까진 내가 요청한 데이터를 서버가 선뜻 내어주려고 하지 않는다. 서버 그는 그리 쉬운 사람이 아니다. 먼저 스몰 토크를 통해(?) 친밀감을 쌓아야 하기 때문이다. 이렇듯 브라우저가 서버와의 연결 준비를 하는 이 행위를 TCP three-way handshake라고 한다.

TCP(Transmission Control Protocol)은 IP 네트워크 상 두 대의 컴퓨터의 연결 기반 커뮤니케이션을 위한 Transport Layer host-to-host 프로토콜이다. TCP는 three-way handshake를 통해서 IP 기반 네트워크에 TCP/IP 연결을 설정한다. 이 three-way handshake는 'TCP-handshake', 'three message shake' 또는 'SYN-SYN-ACK'라고 불리기도 한다. 이 외계어같은 'SYN-SYN-ACK'의 SYN, ACK가 각각의 메시지 하나를 뜻하기 때문에 three-way 또는 three message라고 불리는 것이다. (이 메시지의 SYN는 synchronize의 첫 세글자, ACK는 acknowledgement의 첫 세글자를 의미한다.) 이 메시지의 주고받음을 통해서 (= 이 handshaking을 통해서) 연결을 희망하는 두 컴퓨터는 HTTP 브라우저 요청에 대한 응답 데이터를 보내기 전에 연결 파라미터를 협상하게 된다.
1-3. 서버와의 연결을 준비하라 2편 (TLS Negotiation: HTTPS 연결을 위해)
HTTPS상에서 좀더 안전한 연결을 위해선 TCP Handshake에 더해서 또 다른 handshake를 해야하는데 (손이 남아나질 않겠어?!) 그게 바로 TLS Negotiation이다. 이번 handshake에선 3번의 클라이언트-서버 왕복 여행이 이루어지는데, 아래 내용들이 오간다:
(1) 어떤 cipher를 사용해서 커뮤니케이션을 encrypt할거니
(2) 서버 verification
(3) 보안 연결 설정 확인

이렇게 보안 연결을 하는 동안, 페이지 로딩엔 그만큼의 시간이 더해진다. 즉, 대기시간(latency)가 증가하게 된다.
2. 서버: 응답 (Response)

서버, 그에게 연결하기 위해 가지고 있던 유일한 정보, 그의 주소라고 생각했던 도메인을 살포시 주소창에 적는다... 하지만 알고보니 그건 찐 주소를 가르키는 이정표같은 것이었고 그렇게 이정표를 따라 DNS 네임 서버에서 찐 주소를 얻었다. 그래서 이제 드디어 좀 만나나 싶었더니 본격적인 비즈니스를 논하기 전에 자꾸 그렇게 악수를 하자고 한다요즘 같은 시대에...
그렇게 원하는데로 TCP handshake와 TLS negotiation을 거쳐, 드디어, 웹 서버와의 연결이 성사 되었다. 이제서야 브라우저는 최초의 HTTP GET 요청을 보내게 된다. 이 요청을 서버가 받으면, 서버는 응답 헤더와 주로 HTML의 컨텐츠를 보내게 된다.
유저가 서버에 요청을 보낸 그 순간부터 (예: 링크를 클릭한 그 순간부터) HTML 첫 패킷을 전달받을 때까지 걸린 시간을 'Time to First Byte(TTFB)'라고 한다. 이 TTFB엔 DNS lookup부터 각종 handshake하는데 걸린 시간까지 모두 포함된다. (출처)
서버가 보낸 첫 컨텐츠의 사이즈는 주로 14kb인데, 거기엔 다 사연이 있다. 바로 'TCP slow start'라는 알고리즘 때문이다. 이 알고리즘은 네트워크 연결 속도의 밸런스를 맞춰주는 역할을 한다. 어떻게?!
14kb였던 최초의 패킷을 브라우저가 받으면, 그 다음 패킷의 사이즈를 그 2배인 28kb가 되도록 설정해서 보낸다. 그리고 이후 패킷들이 임계점에 도달하거나, 또는 congestion이 발생해서 "이건 무리야!! 제.. 제발 그만!"하는 상황이 될 때까지 계속 사이즈를 늘린다. 그러면서 네트워크의 최대 대역폭(bandwidth)을 파악하는 것이다. 이러한 TCP slow start 알고리즘의 작동 방식으로 인해, 웹 성능 최적화를 고려하는 측면에서, 첫 페이지 로딩의 14kb를 고려해야한다는 황금룰(?)이 생겨나게 되었다고 한다.
그러나, 꼭 그래서 이 14KB 황금룰을 지켜야하느냐에 대해선 반대 의견도 있다. 우선 이 첫 패킷이 14KB 이기 때문에 HTML을 그 이하 사이즈로 만들어라, 라는 말들이 있었다고 하는데 사실 그 가장 먼저 보내지는 첫 패킷의 사이즈를 HTML 혼자서 차지할 것이라고 생각하면 안된다고 한다. 그 작은 14KB를 차지하는데엔 요청 헤더 등의 내용도 포함된다는 것이다 (출처). <- 출처에 따르면, 14KB라는 매직 넘버는 사실 그냥 잘못된 추정(assumption)에 기반한 것이고, 그렇기 때문에 이 매직 넘버에 너무 신경쓰면서 14KB를 맞추지 못했다고 슬퍼할 필요는 없다고 한다.
3. 클라이언트: 파싱 (Parsing)
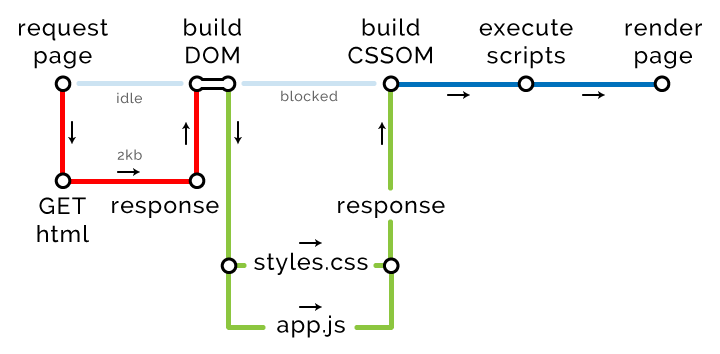
이제까지 주소창에 도메인 주소를 쓰고 엔터를 누른 뒤 많은 일들이 있었다. 우선 DNS 네임 서버에 들려서 IP 주소를 얻었고, 그 얻은 주소를 기반으로 방문하고자하는 사이트의 서버에 문을 두들기며 악수도 하고 협상도 했다. 그러자 만족한 서버는 드디어 우리에게 응답을 전달해줬다. 그럼 그 뒤에 일어나는 일은 우리의 브라우저가 그 데이터를 가지고 무엇을 어떻게 하는지에 관한 일이 된다!
서버로부터 데이터를 전달받으면, 이제 브라우저는 그 받은 데이터를 파싱(parsing)할 수 있게 된다. 이 파싱은 네트워크를 통해 전달받은 데이터를 DOM 트리와 CSSOM으로 변환하는 작업을 뜻한다. 파싱해서 나온 DOM과 CSSOM은 스크린에 페이지를 랜더링할 때 사용되게 된다.
3-1. DOM (Document Object Model)
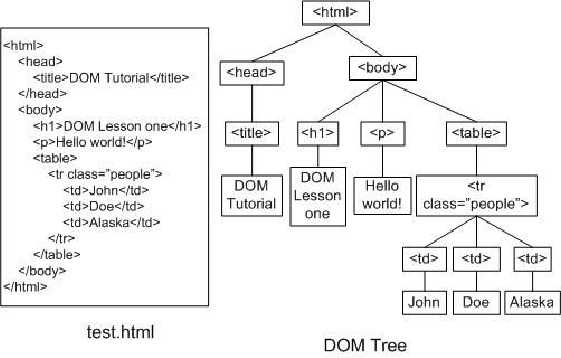
HTML 파싱엔 (1) 토큰화(tokenization)와 (2) 트리 구축이 포함된다. HTML 토근엔 시작/끝 태그들과 속성의 이름과 값들이 포함된다. 브라우저의 Parser가 토큰화된 인풋들을 문서로 분석하고, 그걸 기반으로 DOM 트리를 만든다.
DOM 트리는 다큐먼트의 내용을 보여주는데, DOM 노드의 수가 많을 수록 트리를 구축하는데 오랜 시간이 걸리게 된다.
Parser는 HTML 마크업을 쭈욱 읽어나가게 된다. 문서 내부 내용엔, non-blocking resources로 구분되는 것들이 있다. images, media files, 그리고 <body> 태그 안에서 가장 밑에 작성된 <script> 태그 등이 이에 해당된다. 이 태그들이 non-blocking으로 구분되는 이유는, Parser가 문서를 읽어나가다가 얘내들을 만나도 parsing을 멈추지 않고 그대로 진행하기 때문이다. 동시에 브라우저는 해당 리소스를 얻기 위한 요청을 보낸다. 파싱이 멈추지 않고 진행되기 때문에 non-blocking resource로 분류된다.

파싱은 CSS 파일을 조우(?)할 때도 지속된다. 다만, async나 defer가 붙은 <script> 태그를 만나면 HTML의 파싱을 잠시 멈추게 된다. 그렇기 때문에, 스크립트 파일이 너무 크다면 병목현상(bottleneck)이 발생하게 되는 것이다.
** 여기서 잠깐!
브라우저엔 preload scanner(= 사전 로드 스캐너)라는 것이 있다. 이 사전 로드 스캐너는 HTML에 우선 순위가 높은 리소스들 (<link>로 연결된 CSS 파일 이라던가, 웹 폰트라던가)와 같은 것들을 HTML parser에 의해 생성된 토큰들을 보고 알아차린다 (출처). 그런 다음에, 미리 해당 리소스들에 대한 요청을 해놓는다. 이 사전 로드 스캐너 덕분에, parser가 리소스를 참조하는 부분에 도달해서 요청을 보내고 할 때까지 기다릴 필요가 없어진다. HTML parser가 외부 리소스가 있는 부분에 도착한 시점엔, 리소스가 다운되고 있거나 이미 준비 완료가 되는 아름다운 시츄에이션이 펼쳐지는 것이다! 😍
3-2. CSSOM (CSS Object Model)
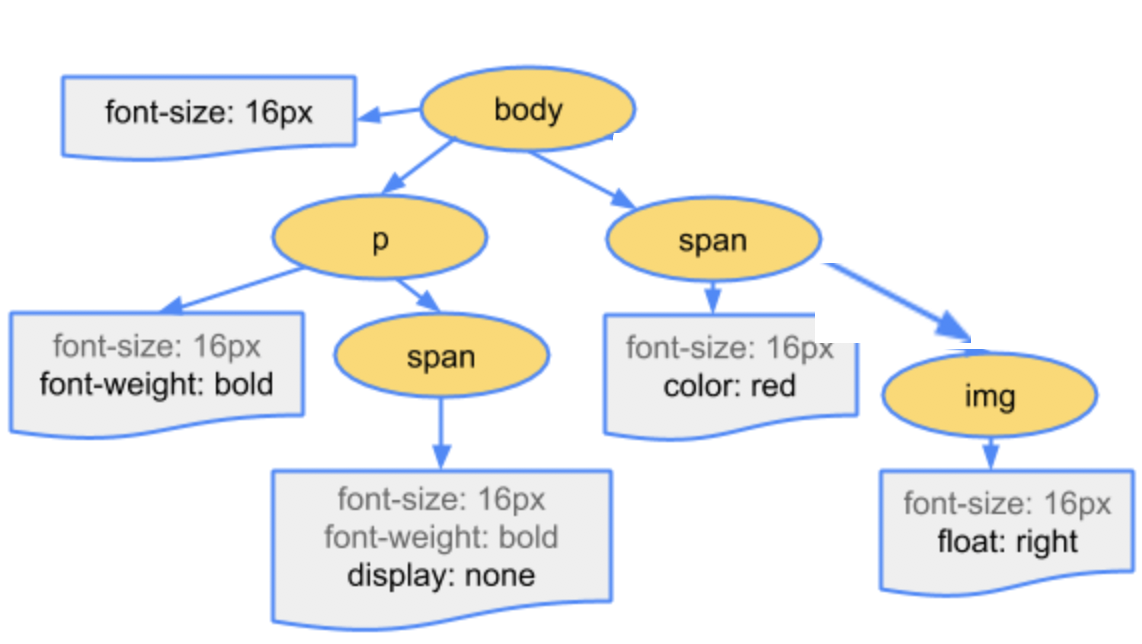
CSSOM은 Document의 스타일 관련 정보를 읽고 수정하는 API들의 묶음이다. DOM과 마찬가지로, CSSOM 또한 트리 형태로 구축된다. 자바스크립트가 DOM을 사용해서 문서의 구조와 컨텐츠를 읽고 쓰고 할 수 있게 되는 것처럼, CSSOM은 자바스크립트가 문서의 스타일링을 읽고 수정하게 해준다.
CSSOM 트리를 만들 때, 브라우저는 유저가 전달한 스타일 시트( = user agent style sheet)를 포함해서, 노드에 적용할 수 있는 가장 일반적인 규칙부터 시작한다. 점점 더 상세한 규칙들을 적용시키면서 계산된 스타일들을 재귀적으로 정제해나간다. 이 작업을 일컬어서 속성값들을 cascade한다고 표현하는 것이다.
CSSOM의 구축은 정말 빠르다고 한다. (혹시라도 시간이 궁금하다면, 개발자 도구의 Recalculate Style 부분에서 CSS를 파싱하고, CSSOM을 구축하고, 재귀적으로 스타일 계산을 하는데에 걸리는 총 시간을 참조할 수 있다고 한다!)
어쨌든, 애초에 CSSOM은 정말 빠르게 구축되기 때문에, 웹 성능 개선을 목표로 잡고 있을 땐 차라리 여기 말고 다른 곳에서 최적화를 얻으려고 노력하는 것이 더 낫다는게 MDN 페이지의 설명이다. (보통 한 개의 DNS lookup을 하는 것보다 CSSOM 하나 만드는 것이 더 빠르다고 한다)
** Critical Rendering Path
그렇게, 서버로부터 도착한 데이터를 DOM과 CSSOM으로 변환하는 작업인 파싱을 거쳤다. 그 다음엔, MDN의 페이지에서 언급하길 Critical Rendering Path라 불리는 일련의 과정을 거쳐야 한다. Critical Rendering Path란, 브라우저가 HTML, CSS, 그리고 Javascript를 스크린 상의 픽셀들로 표현하기까지 거치는 일련의 과정을 뜻한다. 이 과정은 아래와 같이 5가지 단계로 구성되어 있다:
1. HTML 마크업 처리 & DOM 트리 생성
2. CSS 처리 & CSSOM 트리 생성
3. DOM과 CSSOM을 합쳐서 Render tree 구축
4. 레이아웃을 실행시켜서 각 노드의 구조 계산
5. 개별 노드를 스크린에 그리기
4. Render
자, 이제 드디어 마지막 단계이다!
방문하고 싶은 사이트의 도메인 주소를 가지고 IP 주소를 얻고, 그 사이트의 서버를 찾아갔다. 그 다음 서버와 열심히 손들을 흔들어서 친밀도를 쌓았고, 드디어 첫 응답 데이터를 받았다. 그 데이터를 가지고 파싱을 진행해서, 이제 DOM 트리와 CSSOM 트리가 우리 책상(?) 위에 놓이게 되었다. 그 다음으론 이 두 개의 트리를 가지고 무언가를 해야할 차례이다.
이 차례도 세부적으로 단계를 구분할 수 있는데, 이들을 모두 통틀어 Render 단계라고 할 수 있다. 이 단계에선, 앞선 파싱 단계에서 만들어진 DOM 트리와 CSSOM 트리를 합쳐서 하나의 렌더 트리로 만들고, 이 렌더 트리를 사용해서 화면에 보여지는 모든 엘리먼트의 레이아웃을 계산한다. 그리고 나서 화면에 엘리먼트들을 그려주는 것까지 랜더 단계에 포함된다고 할 수 있다. 이 일련의 작업들은 다음과 같은 세부 스탭으로 이름지어서 나눌 수 있다:
(1) Style
(2) Layout
(3) Paint
(4) Compositing (if any)
4-1. Style

랜더 트리(Render tree)란 DOM 트리와 CSSOM 트리를 합쳐서 만든 트리를 의미한다. 스타일이 적용된 것이기 때문에 Computed style tree라고도 불린다. 랜더 트리를 만드는 작업은 우선 DOM 트리의 루브 부터 시작해서, 보여지는 (visible한) 모든 노드를 순회한다. 여기서 'visible'하다는 노드들이 있다면, 분명 '보여지지 않는(invisible)'한 노드들도 있다는 말이 되는데, 그렇다면 어떤 것들이 보여지지 않는 노드일까?
대표적으로, <head> 태그나 그 안의 모든 태그들은 보여지지 않는다. 또한, CSS 스타일로 display: none인 엘리먼트 또한 보여지지 않는 것으로 분류되어 랜더 트리에 포함조차 되지 않는다. 반면에, display: none과 비슷한 용도로 간혹 사용되는 visibility: hidden 속성은 랜더 트리에 포함이 되기 때문에 두 속성을 사용할 때 유의할 필요가 있다. 또한, <script> 태그 같은 경우, 디폴트 설정에 별도로 변경 사항을 주지 않는한 랜더 트리에 포함되지 않는다.
이렇듯, 랜더 트리를 만드는 작업에선 모든 보여지는 노드들을 순회한 다음에 그들에게 CSSOM 트리에서 얻은 규칙을 적용한다. 그럼으로인해 랜더 트리 안엔 모든 보여지는 노드들과, 그 노드들의 컨텐츠 및 계산된 스타일이 더해지게 된다 (위에 랜더 트리 그림을 참고하면 이해가 쉽다! 😃). 그리고선 CSS의 cascading에 따라서, 각 노드에 어떤 스타일들에 적용될 것인지 최종적으로 정해지게 된다.
4-2. Layout
랜더 트리가 다 만들어지면 레이아웃 과정이 시작된다. 랜더 트리는 어떤 노드에 어떤 스타일링을 입힐지까진 관여하지만, 그 이후 각 노드가 어떤 위치에 배치되고 보여질지엔 관여하지 않는다. 그 부분은 레이아웃 단계에서 진행이 되기 때문이다. 레이아웃(Layout)은 랜더 트리에 포함된 모든 노드의 너비와 높이, 그리고 페이지상 이들의 사이즈와 위치를 정하는 프로세스를 지칭한다.
화면에 보여질 오브젝트들의 정확한 사이즈와 위치를 계산하기 위해서, 브라우저는 랜더 트리의 루트 노드에서부터 시작해서 모든 노드를 순회한다. 이 단계에서 브라우저는 디바이스의 viewport size를 고려하게 되며, 이 viewport 사이즈를 기반으로 각 요소의 box model 속성을 고려하면서 <body> 내 모든 자손들을 살펴나간다. 동시에, 이미지같이 크기가 지정되지 않아서 브라우저가 그 크기를 알 수 없는 엘리먼트들을 위해서 placeholder space도 제공된다.
이러한 과정을 거쳐 노드들의 크기와 위치가 정해지는 첫 행위를 layout이라고 하는 것인데, 그 이후 이뤄지는 노드 사이즈나 위치에 대한 재(re) 계산은 reflow라고 불린다.
4-3. Paint 🎨
드디어, 페인트 단계가 되면 개별 노드들이 스크린에 그려지게 된다. 이 페인트 단계에서 브라우저는 레이아웃 단계에서 계산된 각 박스들을 스크린 상의 실제 픽셀로 전환하는 것이다. 이렇게해서 가장 처음 그려진 그림을 'first meaningful paint'라고 부른다. '왜 가장 처음 그려진 것을 따질까? 원래 한번 그려지면 끝아냐?!'라고 할수도 있다(내가 그랬다). 그런데 애니메이션 등이 올바르게 나오려면 한번의 페인트로 끝나는 것이 아니라 여러번 repaint되어야 하기 때문에 그렇다.
부드러운 스크롤링과 애니메이션을 유지하려면 스타일 계산이나 reflow나 repaint 등 main thread를 차지하는 모든 행위들이 16.78ms 이내에 완료되어야 한다고 한다 (출처). 또한, 최초 페인팅 이후 실행되는 repaint가 최초보다 더 빠르게 진행하기 위해서 여러 레이어로 분산해서 그리는 방식이 있는데, 이렇게 레이어를 만들 수 있는 요소들과 속성들이 따로 있다. <video> 태그나 <canvas> 태그, 그리고 CSS 속성 중 opacity나 3d transform이 이에 해당된다고 한다.
이러한 레이어로 분할이 가능한 요소들에 한해서, 페인팅 단계에서 브라우저는 레이아웃 트리의 요소들을 여러 레이어로 분할을 한다. 이렇게하면, 페인트 & 리페인트 기능을 main thread가 돌아가는 CPU가 아니라, GPU가 나누어서 처리하기 때문에 성능이 향상된다. 유의해야할 점은, GPU의 도움으로 성능이 향상될 순 있지만 이렇게 작업을 하게 되면 메모리가 많이 소요된다는 것이다. 그래서 웹 성능 최적화를 목적으로 하는 경우에 레이어화를 너무 남용하는 것은 좋지 않다고 한다.
🤔 웹 성능 개선... 무엇을 할 수 있을까? 🤔
지금까지, 유저가 브라우저의 주소창에 도메인을 적거나 링크를 클릭한 순간부터 유저의 스크린에 요청한 페이지가 그려지기까지 어떤 일들이 발생하는지를 살펴보았다. 이에 대한 이해를 바탕으로, 웹 성능 개선에 관해선 어떤 인사이트를 얻을 수 있을까? 아직 생각나는 사항들은 아래 밖에 없는데, 혹시 이 글을 읽으신 분들 중 더 좋은 아이디어가 있으신 분들이 댓글을 남겨주신다면 너무 감사할 것 같다. 😍👍
=> 다른 호스트명을 사용하는 DNS lookup을 최소화한다. 동일한 hostname의 에셋들을 사용하던가 아니면 그 수를 줄이던가 해야한다.
=> TCP handshake는 필수로 진행되어야 하는 것이고, 보안을 위해선 HTTP보단 HTTPS이니 TLS negotiation으로 인해 증가하는 latency는 어쩔 수 없는 것 같다. 보안은 중요하니까!
=> 대역폭이 크면 그만큼 더 많은 데이터를 더 빨리 보낼 수 있다.
=> 좋은 하드웨어와 네트워크 상태를 유지하면 당연히 좋다.
=> HTML의 사이즈를 줄여라! 다만 14KB라는 숫자에 얽매여 그 숫자 이하로 사이즈를 맞추기 위해 엄청나고 강력한 노력을 굳이 하진 않아도 된다.
=> 요청한 페이지의 HTML이 매직 넘버 14KB 패킷보다 크다고 하더라도, 브라우저는 일단 처음 받은 그 불완전한 데이터를 가지고서라도 파싱 및 랜더링을 시도한다. 그렇기 때문에, 적어도 첫 랜더링에 필요한 CSS와 HTML의 템플릿 만이라도 첫 패킷에 들어갈 수 있도록 작업을 한다면 웹 성능 최적화에 이득을 줄 수 있지 않을까.
=> 가능하다면, 스크립트 파일의 사이즈를 줄이는 것이 파싱 단계에서의 병목현상을 피하는데에 도움이 된다. 불필요한 라이브러리나 사용하지 않는 페이지의 코드 등은 미리미리 삭제하는 것이 좋다.
=> 불필요하게 깊은 DOM 구조는 피하도록 하자. reflow에서 DOM 트리 재생성에 시간이 추가될 수 있다.
=> CSS 샐럭터는 최대한 직관적으로, 복잡한 구조를 피하면서 작성하자. reflow에서 시간이 많이 걸린다.
=> 이미지나 비디오의 사이즈를 명시하자. 랜더 단계에서의 reflow를 줄일 수 있다.
'Learn to Code' 카테고리의 다른 글
| [프로젝트] React Drag&Drop: 투두리스트를 칸반 보드로 (2) (feat. getBoundingClientRect()) (1) | 2021.08.26 |
|---|---|
| [프로젝트] React Drag&Drop: 투두리스트를 칸반 보드로 (1) (0) | 2021.08.25 |
| [JS] 즉시실행함수(IIFE)란? (0) | 2021.08.19 |
| [JS] event loop이란? (0) | 2021.08.18 |
| Intersection Observer API: 스크롤링에 따라 엘리먼트가 짠!하고 나타나게 해주는 애니메이션을 만들고 싶을 때 (0) | 2021.08.18 |




댓글